Indexing
Indexing is a Reality feature which increases the speed of access to file data. Reality processors, including English and DataBasic, can use indexes. Also the SELECT-INDEX and ISELECT commands provide active lists, usable by TCL-II and English. English uses suitable indexes automatically. Other processors use named indexes only.
An index is created using CREATE-INDEX command, based on either:
- An index definition created using the DEFINE-INDEX command.
- A data definition item in the file dictionary.
Once an index has been created, it is kept up to date automatically by Reality. Each time Reality opens a data section, it checks the D-pointer for associated indexes and whenever an item is updated all index entries are checked. It calculates the old and new key values, and if the key value has changed, it deletes the old index entry and adds the new one. However, if the item no longer matches the selection criteria, or if it has been deleted, its entry is removed altogether from the index.
Notes
- Automatic index maintenance applies only to data actually in the data section. A change to external data referenced via a data definition item used in the index does not cause the index to be updated.
- Because indexes are updated automatically, they may need to be periodically resized to optimise performance and avoid wasting disk space. For this reason, it is strongly recommended that all indexes should be automatically sized. By default, all new indexes are configured to use automatic sizing and existing indexes will be configured to use automatic sizing if they are restored from a logical save. For details of how to convert an index to use automatic sizing, refer to the description of the AFS-ENABLE command. Calculating the best initial modulo for an index is described in Selecting the Modulo for an Index.
- When a index is created, the current Environment Options settings are used. These settings are stored with the index definition and are used in subsequent automatic updates, thus ensuring that changes to the environment options do not cause unexpected changes in the index.
The following points should also be noted when using indexes:
-
Only data sections may be indexed.
-
Index sections may not be opened, read or modified explicitly.
-
If you are running Transaction Logging or Rapid Recovery, for any file that is Logged or Recoverable, the index is also recoverable.
-
Indexes are file-saved and file-restored if the associated file is saved and restored.
-
Indexes should be created only when a file is not being updated, to prevent invalid data being compiled in the index.
-
Any number of indexes may be associated with a data section. However, the number of indexes to a file should be kept to a minimum because each index definition has to be checked when a file item is updated and each index takes up disk space according to the number of items in the index, the average size of item-ids, the sort criteria used and the size of values in the attributes sorted on.
Accessing indexes
An index can be explicitly accessed by TCL or DataBasic. Both processors can reference any number of entries or range of entries across an index. In addition, where a data section has associated indexes, English may use one of these to access the data section.
Using SELECT-INDEX and ISELECT
SELECT-INDEX and ISELECT both generate an active item list from an index. You can specify individual key values, or ranges of key values.
Using DataBasic
To access an index from DataBasic, you attach a variable to an index with the SELECT statement. You can then read the next or previous item-id relative to a pointer via the READNEXT or READPREV statements. Both statements give you the option of retrieving the key value for each item-id. You can use the POSITION statement to move the pointer within the index.
Use of indexes by English
The English processor's speed of execution can be increased significantly if it is able to use an index to access the data section. English will use an index if the selection and sort criteria of the index correspond to the English statement's selection or sort criteria according to the following rules:
-
The index must contain all items in the file (its definition does not include selection criteria).
-
The selection in the English statement is on the item-id: an index sorted primarily by item-id is then used.
-
The selection in the statement is on a specific attribute: an index sorted primarily by that attribute is then used.
-
The selection in the statement must be based on a left-aligned complete or partial string.
-
If selection criteria are ANDed, either for the item-id or for the Data Definition Item, the use of the index is based on the left-most ANDed value.
-
The index is not used if there is ORed selection.
-
If there is no selection, but the sort criteria matches an index definition exactly, the index is used.
In the following examples, English uses a suitable index if one is available. Note that item-id selection always precedes and is implicitly ANDed with attribute selection criteria.
LIST FILE = '12]'
Uses an index that has no selection criteria, so that it contains all items in the file, which is also sorted by item-id . Rules 1, 2 and 4 are obeyed.
LIST FILE = '[12]'
Does not use an index, as the selection criterion in the statement is not left-aligned. Rule 4 is obeyed.
LIST FILE = '12]' AND = '[X'
Uses an index as in the first example. Rules 1, 2, 4 and 5 are obeyed.
LIST FILE = '12]' = '3]'
Does not use an index as the item selection criteria in the statement are implicitly ORed. Rule 6 is obeyed.
LIST FILE WITH DDI = "12]"
Uses an index that contains all file items, sorted primarily by attribute DDI. Rules 1 and 3 are obeyed.
LIST FILE = '12]' WITH DDI = "[ABC]"
Uses a complete index sorted primarily by item-id. Rules 1, 2, 4, and 5 are obeyed.
LIST FILE WITH DDI = "12]" AND = "[X"
Uses a complete index based primarily on attribute DDI. Rules 1, 3, 4, and 5 are obeyed.
LIST FILE WITH DDI = "12]" = "3"
Does not use an index as there is an implicit OR in the statement. Rule 6 is obeyed.
LIST FILE WITH DDI = "12]" AND WITH YYY = "ABC"
Uses a complete index sorted primarily on DDI. Rules 1, 3 and 5 are obeyed.
LIST FILE WITH DDI = "12]" WITH YYY = "ABC"
Does not use an index because the selection criteria are implicitly ORed. Rule 6 is obeyed.
SORT FILE
Uses a complete index sorted primarily by item-id. Rules 1 and 7 are obeyed.
SORT FILE BY DDI
Uses a complete index sorted primarily on DDI. Rules 1 and 7 are obeyed.
TCL Commands for Managing Indexing
The following TCL commands are provided to set up, remove, verify, select and view an index:
Defining an index
To define an index you use the DEFINE-INDEX command. This creates an index definition item in the associated file dictionary with the index name as its item-id.
The index definition item contains both the source and a compiled form of the selection and sort criteria. These are specified via the DEFINE-INDEX command exactly as they would be in an English command. The referenced data definitions are compiled as defined when DEFINE-INDEX was executed - if you change any of the data definitions you must remove the index and its definition (see Deleting an Index) and then redefine and create it again. Refer to the section Index Definition Item for a description of the index definition item structure.
Note that the definition item only defines the index structure; it does not create the index.
DEFINE-INDEX also allows you to recreate an index definition from its associated index. This allows you to recover a corrupt index definition, or one that has been deleted in error.
Creating an index
To create an index, you must use the CREATE-INDEX command and specify the index name as a parameter - the index name can be the name of an index definition item created with DEFINE-INDEX or the name of a data definition item in the file dictionary. An index section is created with an entry for each item in the specified data section that matches the selection criteria.
Note
If you create an index from a data definition item, you do not need to first create an index definition.
When you create an index from an index definition, the entries are ordered in the index according to their sort 'key value', developed from the sort criteria. Each key value is made up of the values of the attributes sorted on, if any, with the item-id as the least significant portion. If sort criteria are not specified, then the item-id is the key value.
When you create an index from a dictionary definition, you can specify various options to determine the features of the index (for example, whether the index is sorted in ascending or descending order). See CREATE-INDEX for details.
Note
Unless you specify otherwise the index will be configured for automatic file sizing.
Verifying an index
To verify that an index is created correctly for a particular data
section, you use the
Deleting an index
To remove an index section you must use the DELETE-INDEX command. To remove the index definition, you must use the English command EDELETE with following syntax:
EDELETE DICT file-name 'index-name'
Ensure that you use the correct case for the index name and enclose it in single quotes.
Changing an index
To change an index definition, you must first delete the index section using DELETE-INDEX. Then, if required, change any data definition items, and if appropriate redefine the index using DEFINE-INDEX, specifying the O option in order to overwrite the existing index definition item. Finally, recreate the index section using CREATE-INDEX.
If you are resizing your index by changing the modulo (see Sizing Files and Indexes), you need only delete the index and recreate the index section.
Viewing an index
You can view the contents of an index by creating a special view file using the MAKE-SPECIAL command. MAKE-SPECIAL can be used to create the following special views of an index:
- Key values for data items selected by the index.
- Item-ids associated with the key values in the index.
Listing indexes
You can list the indexes for a particular file, data section or account using the LIST-INDEXES command. The indexes are verified and any errors reported.
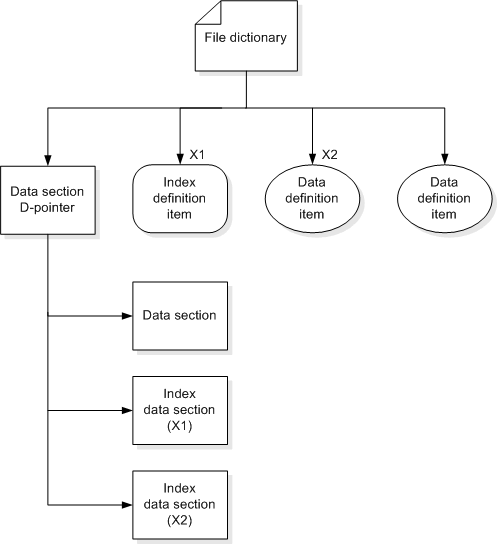
Indexes in the database file structure
The index definition item created by DEFINE-INDEX resides in the file dictionary of the data file with which it is associated. The index section itself is closely connected with the data section to which it relates. The D-pointer for the data section, also points to its index section(s). The construction and maintenance of an index section is transparent to the user in normal operation.
An index is a modified version of the classic Balanced Tree (B-Tree) data structure, containing the item-ids of all items in the associated data section which match specified selection criteria and ordered according to specified sort criteria. The standard B-Tree technique is modified to support and take advantage of Reality's variable length nature. The nodes of the tree are stored in an index section using a hashing technique very similar to that used in a normal data section.
The index structures associated with a file dictionary are illustrated in the diagram below.
Case sensitivity
Because index definitions are based on English, the same rules for case-sensitivity apply. That is:
-
If data case insensitive mode is selected, case is ignored when comparing attribute values.
-
If the file specified in the English sentence has case-insensitive item-ids:
-
The case of item-ids in selection criteria is ignored.
-
When sorting by item-id, the case of item-ids is ignored.
-
-
If keyword case-insensitivity is selected, conversion codes and their operators and operand keywords can be in any combination of upper or lower case.
See Case Sensitivity for details of how to select the different case-insensitive options.