SQL Query Optimisation
Reality processing of an SQL statement is carried out in three main stages.

It is the Optimisation stage that uses Reality indexes in order to maximise the speed of the SQL query.
On receiving the compiled SQL statement, the SQL Optimiser attempts to speed up the query by looking to see if the selection criteria specified in the WHERE or ORDER BY clause can be satisfied using a Reality item-id or index, instead of having to scan or sort the entire Reality file. Predefined rules are used by the optimisation algorithm in order to recognise the Reality item-id or index that matches the SQL statement. These are described later.
Optimisation Methods
The two optimisation methods are:
- Item id Optimisation: SQL uses this method to optimise WHERE clauses. If a column, specified in the WHERE selection criteria, accesses a full Reality item-id, and certain matching conditions are met, the SQL Optimiser uses the item-id referenced in the SQL statement to access the selected item(s) directly without having to search through the whole file. An item-id uniquely identifies an item and to speed up file access, items are stored in groups using a hashing algorithm based on the item-id.
- Index Optimisation: SQL uses this method to optimise WHERE and ORDER BY clauses (where both exist, WHERE clause optimisation takes priority). If the internal index definition in a Reality index matches the SQL column definition, the SQL server uses the index to access the selected item(s) without having to search or sort the whole file. Reality indexes are also employed to speed up file access by the English Processor.
SQL Query Optimisation Rules
Optimisation is performed according to a set of rules that determine which item-id or index is used to speed up the SQL statement selection. Rules used for optimisation are described below.
Rules for Item-id Optimisation
Columns which are item-ids
... WHERE COL = value
... WHERE COL IN ( valuelist )
... WHERE COL IN ( sub-query )
... WHERE COL = ?
... WHERE cola = colb
Where:
value Must be a constant literal, number, string, or expression.
valuelist Is a list of values that can be compared with COL.
sub-query Is select query returning a valuelist.
? Is a value returned from a parameter marker.
colb is part of an outer table in a multi-table query. For example:
SELECT * FROM EMP WHERE EMPNO = '8698'
SELECT EMPNO, ENAME FROM EMP WHERE EMPNO IN ( '90020', '90030' )
SELECT * FROM T1, T2 WHERE T1.ID = T2.X
Rules for Index Optimisation
SQL does not use selective indexes (for example, DEFINE-INDEX SQLEMP WITH DEPTNO = '90010' BY TITLE); the whole file must be indexed.
Note
This rule also applies to English.
Optimisation is used on indexed columns as per the item-id rules above.
Optimisation is also used on indexed columns used with >, <, >=, <= and BETWEEN operators. These are collectively known as range operators.
Note
This is a good reason for defining an index on an item-id column since it allows you to optimise range operations.
The use of Multiple AND/OR Clauses
Given the statement:
SELECT * FROM T1 WHERE COL1 = 'A' OR COL2 = 'B' OR ...
optimisation is possible only if each condition can be optimised. The optimiser checks each condition. If any one of them cannot be optimised then NO optimisation is possible (that is, no indexes are used). COL1, COL2, etc. can be any combination of indexes or item-ids.
Given the statement:
SELECT * FROM T1 WHERE COL1 = 'A' AND COL2 = 'B' AND ...
Optimisation is possible if one or more of the conditions can be optimised.
Join Optimisation
As an example of a simple statement which benefits from join optimisation consider the following:
SELECT E.EMPNO,E.ENAME,D.DEPTNO,D.DEPTNAME
FROM EMP E, DEPT D
WHERE E.DEPTNO = D.DEPTNO
where E.EMPNO and D.DEPTNO are the Primary Keys (IIDs).
Assume, for the sake of calculation, that the EMP table contains 1,000 rows and the DEPT table contains 100 rows.
Without join optimisation, this query searches the entire DEPT table to find a matching department (DEPTNO) row for each employee in the EMP table. The entire statement then involves 101,000 item reads.
Explanation: For each employee the query reads 1 row from the EMP table and 100 rows from the DEPT table. This is repeated for every one of the 1000 employees, hence the total number of item reads is (1+100) x 1000 = 101,000
With join optimisation the query can accesses the department item directly for each employee, thus the optimised statement requires only 2,000 item reads.
Explanation: For each employee the query reads 1 row from the EMP table and 1 row from the DEPT table (using IID optimisation). This is repeated for every one of the 1000 employees hence the total number of item reads is (1+1) x 1000 = 2000.
Optimisation Strategies
The optimiser employs different optimisation strategies depending on its analysis of the SQL statement and the type of join used.
Cross Join (Independent Tables)
If the WHERE clause does not include a join condition. The optimiser treats each table independently.
Note
A join condition is an expression that matches a column in one table with a column in any other table.
For example, queries such as the following can be fully optimised
SELECT * FROM T1, T2 WHERE T1.ID = 'X' AND T2.ID = 'Y'
where T1.ID and T2.ID are both IID or Indexed columns.
Inner Join (simple case)
An inner join is a cross join with a join condition (see Cross Join) in the WHERE clause. For example,
SELECT * FROM T1,T2 WHERE T2.ID = T1.X
A multi-table query such as this is implemented as a pair of nested loops with T1 being read in the outer loop and T2 in the inner loop. See Flow Diagram of Multi-Table Nested Query.
Column values from an outer table are effectively constant for each pass through the inner table. The optimiser can recognise such columns as constants in comparisons with values from inner tables allowing statements such as these to be optimised.
In this example access to table T2 is optimised, thus eliminating the need to search the whole of T2 for every record in T1 (assuming that T2.ID is an item-id or indexed column).
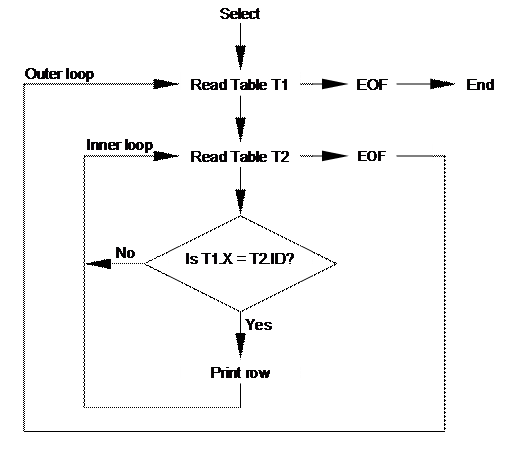
Flow Diagram of Multi-Table Nested Query
Inner Join (complex case)
The optimiser can recognise situations which require the tables to be processed in an order different from that in which they are presented in the SQL statement. For example:
SELECT * FROM T1,T2 WHERE T2.ID = T1.X
can be optimised, but if it were presented as
SELECT * FROM T2,T1 WHERE T2.ID = T1.X
it would not be, although logically identical. T1 in the second statement becomes the inner table and cannot be optimised (assuming T1.X is not an IID or indexed column).
The optimiser looks for cases in which an IID or indexed column from the outer table is compared with a column from an inner table, and attempts to promote the inner table to a position in front of the other table.
In the above example the statement effectively reverts to
SELECT * FROM T1,T2 WHERE T2.ID = T1.X.
and can therefore be fully optimised as in Inner Join (simple case) above.
Outer Join
In an inner join only those rows in both tables that meet the join condition (see Cross Join) are selected. In an outer join one of the two tables is nominated as a master and every row from that table will be included in the output regardless of whether a match exists in the other table. For example
SELECT * FROM {oj T1 LEFT OUTER JOIN T2 ON T2.ID = T1.X}
The optimiser treats ON clauses inside Outer Joins as additional WHERE clause.
The order of the tables in an outer join is crucial, the optimiser cannot re-order them as it can in Inner Join (complex case) above.
LIKE Optimisation
The LIKE operator is used to match a string expression against a 'pattern' that can contain special characters ('_' matches any single character and '%' matches any number of characters, including none).
The optimiser tests for three possible cases:
SELECT * FROM EMP WHERE ENAME LIKE 'SMITH'
SELECT * FROM EMP WHERE ENAME LIKE 'SM_TH%'
SELECT * FROM EMP WHERE ENAME LIKE '%ITH'
If there are no special characters in the LIKE pattern (case 1), the operator behaves as an equality operator, and therefore is eligible for optimisation.
Note
Even if it could not be further optimised the Equals operator is slightly faster than LIKE as it does not have to look for special characters.
In the cases where the LIKE pattern starts with a fixed string, an index can be used to optimise the number of rows that have to be considered. In case 2, an index on ENAME makes it necessary for only those rows beginning with 'SM' to be accessed. In these circumstances, the rows returned by the LIKE clause are a subset of those returned by a similar BETWEEN clause, and can therefore use the same techniques employed for range optimisation. For example, case 2 is similar to:
SELECT * FROM EMP WHERE ENAME BETWEEN 'SM' AND 'SMZZZZ...'
In the cases where a special character is used in the first character position of the LIKE pattern (case 3), no optimisation is possible.
Debugging Features
In order to determine if an index is being used, or what effect it has, you can use the SQL command at TCL to test the SQL statement. The following debugging options are available:
C Turns on the COUNT option (similar to English).
D8 Displays optimisation decisions.
O Turns all SQL optimisation off.
S Turns off sort optimisation.
T Turns off table access optimisation (item-id and index optimisation).
W Turns off multi-table WHERE clause optimisation.
For example:
:SQL SELECT * FROM EMP WHERE ENAME BETWEEN 'SM' AND 'SMZZZZ...' (D8Column definitions may be checked using the SQL VERIFY statement. This has the same syntax as the SELECT statement but with the following differences.
- Normal SELECT output is suppressed.
- All retrieved data is verified by applying the same data validation rules that would be used for new data in INSERT or UPDATE statements.
When run from TCL, the VERIFY statement reports all data errors detected (if run from a PC application, it exits on the first error). For example:
SQL VERIFY EMP
This statement can be used to check that all data in a table matches the SQL column definitions for that table. Any errors it detects may indicate invalid data or a mistake in the column definition.
Index Matching Algorithm
The basis of the matching algorithm is to find an index whose internal definition (the "compiled string") matches the columns used in the query's WHERE or ORDER BY clause. For this matching algorithm to work it is important that the current English data definition items or the current SQL column definitions are expressed in term that exactly match the definition used to create the index. Any slight difference will defeat the algorithm.
Mismatch Problems
When SQL table and column definitions are created they are frequently derived from English data definition items existing at the time. However, sometimes they have to be manually corrected before they can be used reliably. This can be necessary for a number of reasons. Sometimes the English descriptions are just wrong; sometimes there is an important difference in how English and SQL regard the data. English, and indeed Reality itself, is very flexible and forgiving about data types, sizes and the placement of conversions. SQL as a language is the exact opposite. It is very strict about these things and will not work correctly if the data does not match the catalog definition. See Table/Column Definition Design. A natural consequence of manually changing column definitions is that SQL catalog definitions and the English data definition items on systems may not match exactly. If an index is created using the TCL commands it will use the English data definitions. SQL may then not be able to use that index to optimise a query because its column definitions do not exactly match the English definitions used to create the index. Vice versa, an index created from SQL may not be usable by English for the same reasons.
Example of a Mismatch
As an example of index optimisation not being used (when it appears it should be) due to the column definition not matching the index definition, consider the following:
-
Define an English dictionary definition for a Date field:
1. A
2. 0
3. Date
4,
5.
6.
7. D
8.
9. L
10. 10 - Define and Create an index based on this dictionary definition.
- Use SQLM to build a column definition based on the same dictionary definition.
Using this column in an SQL statement you would expect index optimisation to be employed.
SELECT * FROM T1 WHERE DATE = '1995-05-19'
The above statement does not employ index optimisation and the whole file is searched. The problem is caused when SQLM builds the new 'Date' column definition. It ignores the Left Alignment (used in the dictionary definition) and uses Right Alignment which must be used for numeric values (remember dates on Reality are stored as numbers). This means that the comparison of the index definition and the column definition fails and the optimiser decides that no optimisation is possible.
The "missing values" Problem
Consider a Reality file containing the following item:
Item-id: A Attr 1: A11 ] A12 Attr 2: A21 ] A22 ] A23
where "]" represents a multi-value mark. Both attributes 1 and 2 are multi-valued, but have different numbers of values.
In an SQL table based on this file, with columns A1 and A2 marked as exploding, this item will appear as:
|
ID |
A1 |
A2 |
|---|---|---|
|
A |
A11 |
A21 |
|
A |
A12 |
A22 |
|
A |
A23 |
SQL generates three rows from this item and supplies an empty or NULL value for the missing multivalue in attribute 1.
Indexes defined on attributes containing exploded multivalues and subvalues include only the multivalues and subvalues found in the Reality file. Indexes defined on attributes 1 and 2 will therefore contain different numbers of multivalues - an index on attribute 1 will have two entries for this item whereas an index on attribute 2 will have three entries.
Now consider an SQL query such as:
SQL SELECT * FROM T WHERE A1=''
If no indexes have been defined, no optimisation will be done and the third row will be displayed correctly. If, however, an index has been defined on attribute 1, the query will be optimised using this index. Because there is no entry for the third row in the index, this row will not be displayed.
This and similar problems can arise whenever different attributes contain different numbers of multivalues and/or subvalues. You can use the SQL VERIFY statement to identify any potential problems of this type.